Hello, I wonder if there is going to be an option to control the amount of threads the plotting process is going to spin. It feels at least a little odd to see so many threads running when the system has only 16 cores, 24 threads, my example is the i9-12900k.
I think the node suffers from the heavy load of the plotting threads.
For now a solution would be limiting the amount of threads the program is using with some changes to your linux configuration. Though im not sure if this is something that will be available, @nazar-pc may be able to provide some better insight
Linux configuration? Like you want me to limit via numactl, ehm that would only block the bin from using all cores, it would still spawn tons of threads, but then run of less cores? it would be nice to pass to subspace-farmer --threads=32 Please.
This is likely related to the amount of space you pledge. The number of threads is not a problem on its own, things like slow performance or high memory usage are. And solution to that is not thread count control (which is done automatically to a degree already), but rather farmer being better aware of storage resources it manages.
We are working on various improvements to the farming implementation in upcoming releases, you will likely see improvements on all fronts, including thread count, but it is very unlikely that any thread creation control to be exposed to the user.
Agreed, the number itself may not be a problem, it depends what these threads are doing, IO/CPU bound. When the farmer is plotting, I see high CPU load, the threads responsible a that time are CPU bound. I suspect node performance degradation when system is fully loaded plotting. By observation node appears to do better then process priority for node is higher than farmer.
A lot of threads, assume they do concurrent IO, benefit from running against flash based storage. Flash based storage and especially PCIe based, actually only unfold the full potential with concurrent workloads. On the other hand, spinning based storage, does poorly with concurrent IO.
Looking forward to the enhancements. I hope you consider that storage isn’t storage. During the last 10 days my PCIe flash based systems did best, SATA based flash middle and spindles worst, to the point not worth the effort. Thread count matters, especially concurrent IO against spindles, you may consider --hdd-farmer vs --flash-farmer, per sub plots per spindle, ideally you may not have more than one thread, no concurrency.
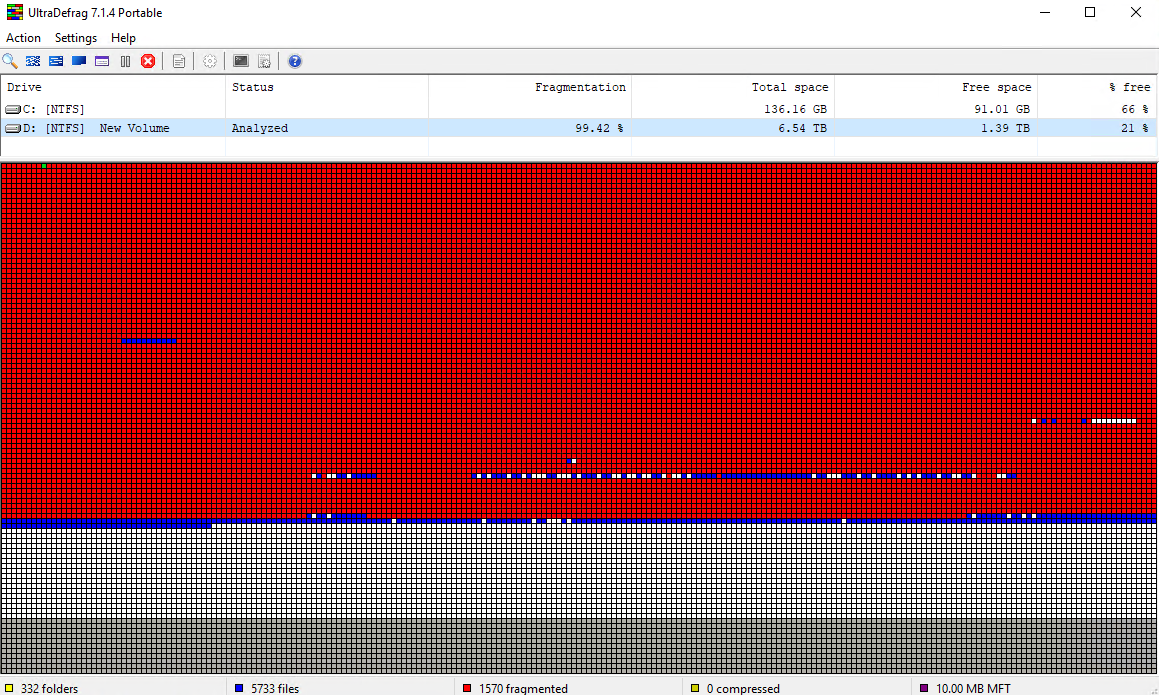
100%. Another issue is the amount of fragmentation during plotting (NTFS / archival node). You won’t feel it as much with SSD, but when trying to plot to HDD it has a tremendous impact.
It’s a RAID0 volume of 6x1.2TB 10K drives. Windows sees it as a single disk with an NTFS volume. I set –plot-size 6000G. Currently the plot dir is 5.09 TB.
I was going to try to replot with the drives set up as a spanned volume rather than a single RAID0, but I have zero incentive now.
Fragmentation tends to depend on a bunch of things.
That explains a lot, when volume is almost full, difficult to just append, more fragmentation happening… Did you try to de-fragment for like say 1 hour… curious what would be the progress? I have one 1 tb plot, per 18 TB HDD. And yes, and when finished plotting, the drive is going to be made full of Chia plots.
I did run a partial defragmentation a number of times during this process. This plotting job has been running for many days now. I’ve also messed with a ~90G RAM cache (pretty pointless but I wanted to anyway).
I think the fragmentation could have been reduced quite significantly by pre-allocating the plots. Since we set the cumulative size in advance, and the maximum/target size of each individual plot is known, I think it should be doable. But I’m not totally up to speed on the plotting process with Subspace, so dunno.