I’ve tried to create farms/plots of varying sizes.
First, I found it useful to create a small-ish archive node, say 100GB, and run it on an SSD. This way I can create additional nodes/farms later and sync them directly from this on my LAN without having to incur any additional WAN traffic (using the --reserved-node and --reserved-only CLI options).
I wanted to fill up an external 2.0 TB USB HDD. I started with a plot size of 1950G. I was unable to sync. When I reached roughly block 26,xxx, the HDD began to thrash and the node was constantly waiting on the farmer. I posted a question in Discord and one of the devs responded by saying this was expected behavior since the farmer was attempting to overwrite some of the data before the initial plotting was complete, thus causing the HDD to thrash. Syncing ground to a halt so I decided to abort.
I tried the exact same thing again, only this time reducing the plot size from 1950G->600G. Same result.
I ultimately decided to do everything on an SSD (2TB NVMe). A couple observations here: Initial sync/plot took several hours. It completed overnight. Once this finished I noticed the salt update process started. The node/farm started to fall out of sync. I then noticed that the CPU load (an 8x/16t Ryzen 1800X) was maxxed out (load average >15) and the I/O throughput on the SSD was VERY high (read throughput was >1800 MB/sec using iotop). After what seemed like an hour the salt update eventually finished and the system stabilized but I still had to restart the node/farmer (docker compose down; docker compose up -d) to get it to start farming again.
I’m really skeptical that an HDD farm is viable given the disk throughput demands. Seems like it could take days or more for these processes to complete. Can the devs comment?
Perhaps the devs could update the farmer to make this a serial process rather than a parallel one? HDDs do not like this type of random I/O. It results in thrashing. It would also explain why the SSD is so much faster at this.
The HDD is only reading at about 17-25 MB/sec. If it were a sustained read by a single thread it would be much higher; perhaps 75-100 MB/sec.
I was trying a 10T plot and my machine was not having it. I figured it was because I was also having issues getting my port to forward. Well, got the port issue worked out - and it was looking like a 10T plot was overwhelming the machine.
I’ve tried plotting 500G on my 4ht gen i5 16GB and it went more or less smoothly. There’s always a point around block 30k where things seriously slow down as teslak mentions, but for me it ended up recovering.
But salt updates are crashing the farmer consistently, so no cigar. Hope your setup works out.
Hey all, so per my previous post I was struggling to get one of my node/farmer pairs past the “salt recommitment” phase that occurs not long after the node finishes its initial syncing/plotting. It’s a 600GB farm located on an external 2.0 TB HDD (USB 3.0).
Symptoms: When salt recommitment starts, multiple threads simultaneously try to access the HDD causing it to thrash. The sustained read throughput was about 20 MB/sec (according to iostat). Unfortunately this created an I/O bottleneck for the accompanying node which could no longer stay in sync (Waiting for farmer to receive and acknowledge archived segment). This caused the node to buffer up blocks in RAM while waiting for I/O. Eventually the machine runs out of RAM and the process crashed.
I tried an overnight experiment: Let salt recommitment start and as soon as it does, bring down the accompanying node (docker container stop node). Sure enough after about 6 hours, the salt recommitment process completed. I just brought the node back up and the farmer began slowly creating new plot segments. It’s currently about 6000 blocks behind the top of the chain and syncing very slowly. I guess we’ll see where this goes…
I saw the same error in my farmer log when I killed the node. But… it’s actually still alive, and if you monitor your disk usage (dstat or iotop) you’ll see that it’s still alive and it’s reading from the plot folder. Give it time. It’ll eventually finish and when it does, you can start the node back up.
Yes tried again and I can confirm. Although in my case the farmer ended up crashing after the salt update completing. I didn’t register the error but maybe I waited too long to restart the node. But now the node got back in sync and farmer is running.
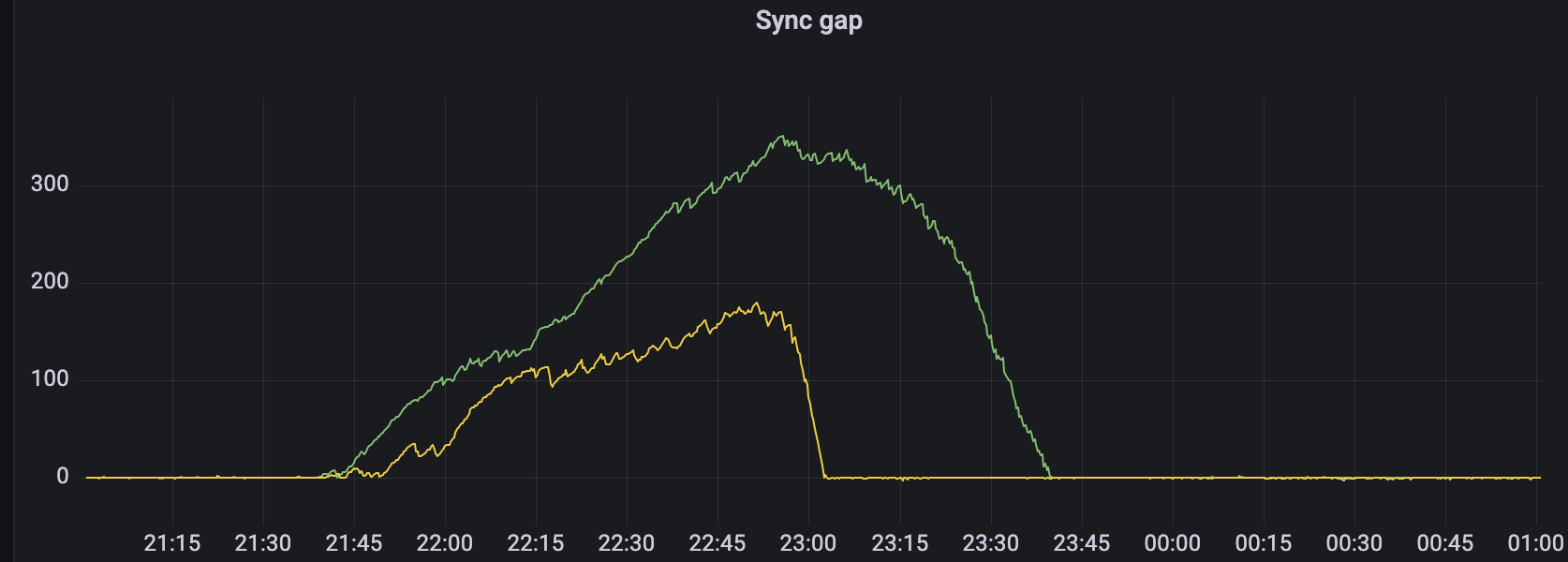
I’ve capture some metrics from grafana for the last recommitment for reference/ comparison with other setups. I’m currently running 2 setups, both on June-13 snapshot:
A. Intel i7 10th Gen, 32GB RAM, RAID0 of 10x10k RPM SATA drives, 4TB plot size
B. Intel i5 4th Gen, 16GB RAM, 1x 10K RPM SATA drive, 500GB plot size. This is also running a Chia node/farmer
Setup A took 2 hours between start of the event and getting back in sync, B being quicker because of the small plot size still took north of 1h with just 500GB - the chart plots the difference between target bloc and current best block from prometheus metrics: